现代unlink漏洞讲解与利用
理解这个漏洞,我花了几天的时间。从学习堆的基础知识到学习unlink.头发掉了不少。嘿嘿嘿。
鸡汤一下:不积跬步无以至千里,不积小流无以成江海。
学习堆的知识也是这样。
现在就说说我学习的总结。
关于glibc的堆的管理基础知识,我就不说了,如果不知道,就查看下面两个链接,我觉得写的不错,我也是照着这个学的。涉及到的unlink的堆的管理细节,我下面还是会拿出来说一说的。
https://www.cnblogs.com/alisecurity/p/5486458.html
https://www.cnblogs.com/alisecurity/p/5520847.html
现在就来说说什么unlink漏洞吧。
我在网上看来很多很多篇的博客,看到有的地方总是解释不清楚或者都是一带而过。所以下面写的这个东西有些是我自己总结的但是大部分都是我再网上学习的。
首先明白unlink会再什么地方使用?
unlink在分配内存和释放之后合并内存的时候使用,但是在分配内存的时候我们不能利用,因为这个时候归glibc管理里面的值。我们在利用的时候是让他合并内存的时候,具体怎么利用我们下面细讲。
unlink是什么?
因为unlink经常使用,所以在glibc中将这个函数变成了一个宏定义:
1 | /* Take a chunk off a bin list */ |
具体的功能用一张图解释吧:
上面的代码和图片总结的来说就是
1 | unlink(p,FD,BK) |
已经说完了什么是unlink了。
接下来讲讲当我们释放内存的时候,怎么使用unlink进行内存的回收。
通过学习glibc的内存管理,我们知道当释放一个内存的时候,会查看相邻的地址是不是空闲的,如果是的话,就进行合并。
接下来就是内存的合并:
合并有两种合并的方式,一个是向前合并,一个是向后合并。
规定向前指的是物理相邻高地址
向后指的是物理相邻的低地址
向前(高地址)合并:判断下一个(高地址)块是不是空闲的。去查看下下个块的p位是不是为0和有没有presize。去访问下一个块,就是将当前块指针加当前块的大小在加上下一个块的大小即可查看到。如果是空闲的,则使用unlink操作去合并它,加入到unsort bin 中。关于unlink,下一步再说。
向后(低地址)合并:直接判断当前的p值是不是为0和有没有presize,如果是0,直接合并。后面就和上面一样。
现在可能看到这里会有些纳闷了,为什么unlink会回收内存,起初我也很纳闷。
注意这个时候FD、P、BK是相邻的。unlink之后,FD和BK的大小直接互指了,中间的P直接融合进FD了。这个时候的FD->size+=P->size。unlink之后会把FD这个大size的chunk放入unsort bin中,不过这个就不是我们操心的事了,关于怎么放和怎么将大内存取下来也和我们这里的unlink漏洞没关系了。
好的 这里就解释的差不多了。我们就直接上一个例子来说吧。结合例子将漏洞会更加的生动。
1 |
|
这是一个编译在linux64位下的一个程序。我也是从别人博客上copy过来的,不过别人的程序并没有打印出这么多个地址,这些只是我验证我的理解的时候加上去的。不过原博客并没有讲清楚这个程序,让我来图文并茂的来讲解这个程序。说实话我挺佩服这个人的,这个例子完美的呈现了unlink的漏洞,简单又直接。不多BB。直接看结果,为什么说是有漏洞。
看到最后两行打印输出的代码了没。
前面定义了一个victim的字符串
后面也没有更改victim的值。
按照道理来说打印victim应该是hello
但是结果:
最后输出的是AAAAA,就是我们ptr0[0] 所赋的值。我们又没有直接操作victim,让victim赋值为AAAAA,所以这里就是我们的漏洞,可以间接实现任意位置的写。
所以我们接下来分析它的代码
首先它定义了两个指针ptr0,ptr1,现在这两个指针当作变量现存放在栈上,现在这个变量上的值是乱码,没问题吧。
然后它又开辟了两块空间,这两块空间的地址给了ptr0,和给了ptr1。所以说现在栈上ptr0的位置上存放这第一块内存的地址,ptr1的位置上存放着第二块内存的地址。这么说有点抽象。画个图。
关于为什么堆上开辟的两块内存为什么连在一块,在回去看一看内存管理的基础知识,我就不再说了。注意我这个大小是0x80,不是从fast bin中分配出来的,是从small bin中分配出来的,所以我之后的内存释放才会调用unlink。
关于为什么他们的大小是0x90,这个也还是基础知识,堆块的基础知识。我这里再讲的话就篇幅大了,所以这里看不懂了就赶快回去补补,基础是硬伤,我就是吃了基础的亏,爬了无数博客写的坑,有些东西也不讲清楚,一直爬一直爬一直爬,一个unlink漏洞我看了几天,tcl。好了扯得有点远了,bb多了,继续回到代码。
1 | ptr0[2]= ptr0[2] = (uint64_t)&ptr0 - 3*sizeof(uint64_t); |
这里要理解数组的作用,ptr0[2],实际上就是ptr0所指向的地址上面,也就是指向的块向下偏移28个字节的地址上面存放这个(uint64_t)&ptr0 - 3sizeof(uint64_t)值。如果这里不能理解,我只想说回去再看看C语言吧。结构体什么的多看看。同理ptr0[3]也是类似的。
为什么要这样做呢
我们是要伪造一个free chunk,然后可以unlink这个free unlink
我们再来复习一下free chunk的结构
看见没,是不是又熟悉感。仿佛又回到了学基础知识的苦海中了。
我们刚才说将(uint64_t)&ptr0-3sizeof(uint64_t)写到ptr0偏移16个字节处,也就是这里的fd。然后(uint64_t)&ptr0 - 2sizeof(uint64_t)写到ptr0偏移24个字节处。好,到了这一步我们就看看(uint64_t)&ptr0 - 3sizeof(uint64_t)到底是什么。&ptr0是不是栈上的地址,然后&ptr0-38,是不是就是ptr0存放的地址向上抬3个单位的地址。如果不清楚这里的uint64_t=8的话,那还是再回去学学C语言。好了,这么说肯定是不行的,不然你们都觉得我说的很抽象,那我就再画画。
就是这么个样子。
然后就是再分析代码。
1 | uint64_t* ptr1_head = (uint64_t)ptr1 - 2*sizeof(uint64_t); |
为什么这里要让ptr1_head指向ptr1之前的两个字节呢。这里也是再伪造。伪造ptr0所指向的地方是free chunk。unlink在合并内存前会判断相邻的chunk是不是free chunk ,有两个判断点,一个当前chunk的size的第一位是不是0,然后还有一个是看当前chunk有没有pre size。所以上面的三句都是为了让unlink误认为我们ptr0指向的地方是free chunk。第二句就是产生pre size ,第三句就是让当前chunk的size的 第一位为零。如果我现在说的这些不能懂,马上回去在看看基础知识。但是你们有没有思考一个问题,就是为什么我们的pre size要写0x80,因为这个写的大小就是我们伪装的free chunk的大小。
好了说了这么多,接着画图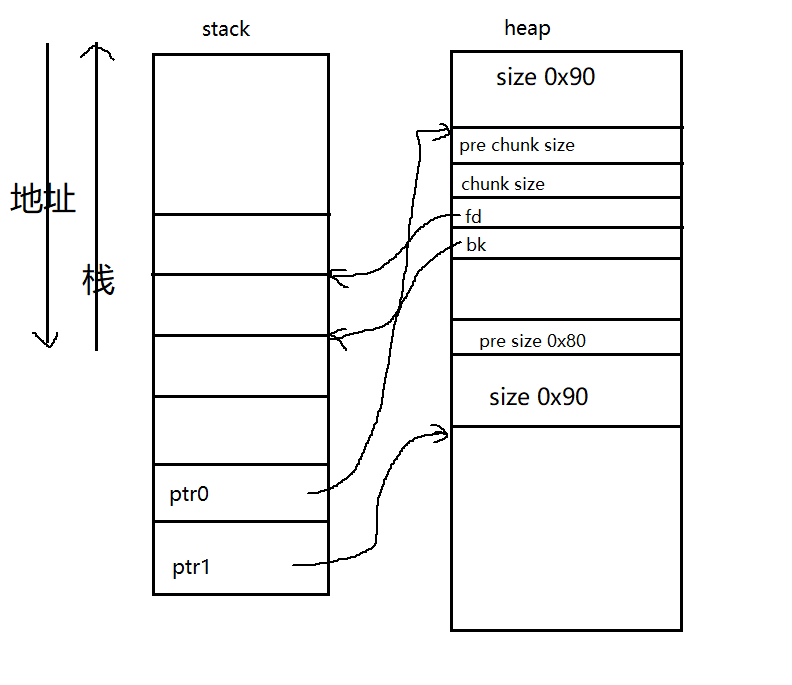
行了,该安排的都已经安排的明明白白了,到了关键的时候了。
free(ptr1)
这里就涉及到了很多东西了,我们慢慢说。
当free(ptr1)的时候,就会判断当前的块前面是不是free chunk.因为我们前面已经伪装好了,所以现在之间使用unlink向后合并。关于向后合并这里我踩了很多坑,开始一直没弄清楚传进去的P指针。这个时候传进去的P指针,是当前P=ptr1-pre size的值。
然后代码就是这样
1 | unlink(P,FD,BK) |
好了,关键时候来了,我们认真的分析一下这个代码。此时我们
1 | P->fd=&ptr0-3*8 |
执行前两句
1 | FD=&ptr0-3*8 |
这个时候
1 | FD->bk=&ptr0 |
然后在执行后面两句
也就是
1 | &ptr0=&ptr0-2*8 |
执行完了之后,也就是&ptr0上面存放着&ptr0-3*8的地址。画图就是这样: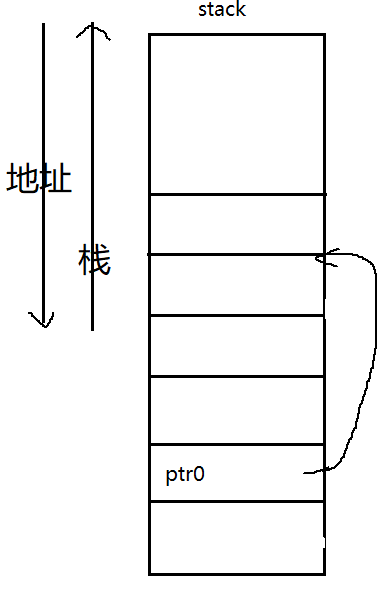
因为ptr1被释放掉了,,所以栈上没有ptr1消失了。然后我们现在
1 | char victim[10] = "hello"; |
这一句就是在栈上在申请一个空间存放字符串”hello”
具体是这样的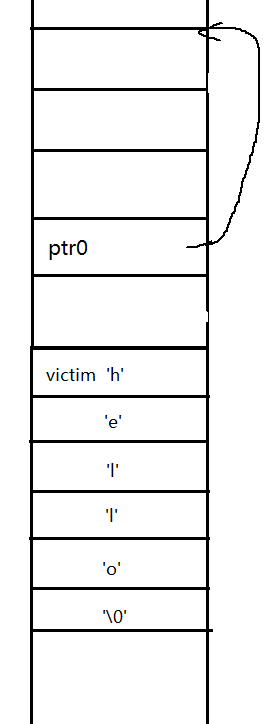
好了,现在我们能操作的的是ptr0。
接着看代码
ptr0[3]=(uint64_t)victim;
这个时候ptr0[3]=ptr0;
也就是ptr0=victim
然后下一句
ptr0[0] = 0x4141414141;
也就是ptr0[0]=victim[0]= 0x4141414141
这里就间接实现了任意位置的写。
也就是为什么最后输出“AAAAA”
总结:
其实现代unlink漏洞的格式是固定的。
在使用这个之前,我们需要确定存放堆指针的地方前38个地方要是可写的。
在这题里也就是栈上的前38个字节。
还需要的就是栈上掌握的指针需要直接操作堆,不能有结构体的偏移,就如这题一样可以直接操作堆指针,这个时候就可以使用unlink漏洞,然后可以直接利用。
然后就是free chunk 的构造格式是一模一样的。
可变的就是ptr0[3]这个地方赋值赋的是要改变的地址addr
然后再给ptr0[0]赋值,赋你想要addr上面写的值。